Microsoft создает самую большую модель генерации языков с 17 миллиардами параметров

Microsoft представляет Turing Natural Language Generation, крупнейшую в мире модель с 17 миллиардами параметров. Она генерирует абстрактные резюме текстовых документов, прямые ответы на вопросы и слова для завершения предложений. Модель отвечает настолько точно, прямо и свободно, насколько это может сделать человек в различных ситуациях.
Крупномасштабные языковые модели глубокого обучения (такие как GPT-2 и BERT) с миллиардами параметров, обученных на всех доступных в интернете текстах, улучшили различные задачи обработки естественного языка (NLP), такие как понимание документов, разговорные агенты и ответы на вопросы.
Было отмечено, что более крупные модели с более разнообразными и всеобъемлющими данными о предварительном обучении работают лучше, даже при меньшем количестве обучающих выборок. Таким образом, гораздо эффективнее обучать массовую централизованную модель и распределять ее функции между различными задачами, а не обучать новую модель для каждой задачи в отдельности.
Следуя этой тенденции, исследователи компании Microsoft представили Turing Natural Language Generation (T-NLG), крупнейшую в мире модель с 17 миллиардами параметров. Оно превосходит существующие стартовые модели по различным параметрам языкового моделирования.
T-NLG может генерировать слова для заполнения незавершенных предложений, резюме входных документов и прямых ответов на вопросы. В отличие от других систем NLP, которые полагаются на извлечение содержимого из документов для создания резюме или ответов на вопросы, новая генеративная модель отвечает настолько точно, прямо и свободно, насколько это может сделать человек в различных ситуациях.

Обучение T-NLG
Поскольку один GPU (даже с 32 ГБ памяти) не может обрабатывать миллиарды параметров, вам нужно распараллелить саму модель или разбить ее на фрагменты, чтобы обучить ее через несколько GPU.
В данном исследовании исследователи использовали аппаратную установку NVIDIA DGX-2 (для более быстрого обмена данными между GPU) и нарезку на тензоры (чтобы разбить модель на 4 графических процессора NVIDIA V100). Используя библиотеку DeepSpeed и оптимизатор Zero, они смогли очень эффективно обучить T-NLG с меньшим количеством GPU.
В этом исследовании исследователи использовали аппаратную настройку NVIDIA DGX-2 (для ускорения обмена данными между графическими процессорами) и тензорную сегментацию (чтобы разбить модель на 4 графических процессора NVIDIA V100). Используя библиотеку DeepSpeed и оптимизатор Zero , они смогли очень эффективно обучать T-NLG с меньшим количеством графических процессоров.
Производительность по сравнению со стандартными задачами

Затем они сравнили производительность предварительно подготовленного T-NLG с другими мощными трансформаторными языковыми моделями по двум стандартным задачам: Точность предсказания следующего слова LAMBADA (выше - лучше) и недоумение Wikitext-103 (ниже - лучше). В обоих случаях T-NLG показал лучшие результаты.
Производительность в ответе на вопрос

Для проверки таких качеств, как грамматическая корректность и фактическая корректность, исследователи обратились за помощью к аннотаторам. Они сравнили новую модель с моделью LSTM (похожей на CopyNet).
Производительность при активном подведении итогов
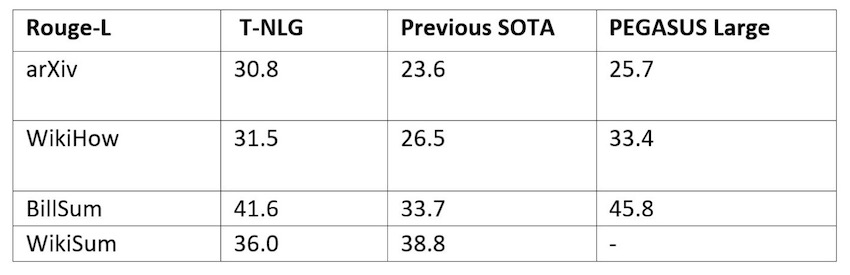
T-NLG может писать человекоподобные абстрактные резюме для различных текстовых документов (включая документы Word, сообщения в блогах, электронные письма, презентации PowerPoint и даже листы Excel), но насколько это хорошо, по сравнению с другими существующими моделями NLP.
Чтобы сделать новую модель более универсальной, чтобы она могла обобщать все виды текста, исследователи обучили ее общедоступным наборам данных обобщения. Затем они сравнили его с другой крупной языковой моделью на основе преобразователя под названием PEGASUS и ее предыдущей версией. На этот раз они сообщили о балле ROUGE - наборе метрик, используемых для оценки автоматического суммирования при обработке естественного языка.
Применение
Microsoft добилась прорыва в разговорном искусственном интеллекте. В ближайшие годы они будут интегрировать T-NLG в пакет Microsoft Office, который не только сэкономит время пользователей, суммируя электронные письма и документы, но также предложит помощь в написании и ответит на вопросы, которые читатели могут задать по поводу контента.
Более того, полученные данные открывают дорогу для более точных, беглых цифровых помощников и чат-ботов, помогая компаниям управлять продажами и отношениями с клиентами.