13 лучших инструментов для анализа данных

Вы когда-нибудь задумывались, какой ключевой процесс стоит за такими достижениями в области технологий, как машинное обучение и дополненная реальность? Ответ - наука о данных.
Наука о данных - это область знаний, объединяющая статистику, информатику, анализ данных и различные смежные методы для понимания сложных закономерностей, скрытых в структурированных или неструктурированных данных.
В ней используются теории и методы, взятые из многих различных областей в контексте информатики, вычислительной техники и знаний о предметной области.
Сегодня в Интернете можно найти множество современных инструментов для извлечения знаний из различных типов данных. Однако не все из них стоит пробовать.
В этой статье мы собрали некоторые из лучших инструментов науки о данных, которые могут быть использованы исследователями и бизнес-аналитиками для получения ценных знаний.
Прежде чем начать, мы хотим уточнить, что в этом списке представлены только инструменты Data Science, а не языки программирования или скрипты для реализации Data Science.
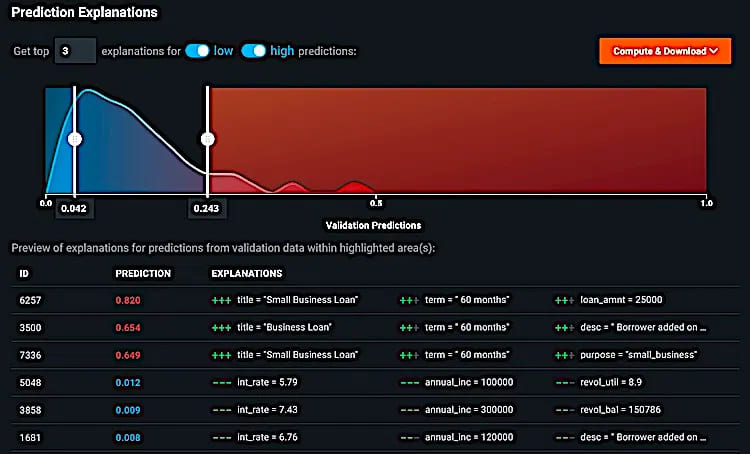
9. DataRobot
Плюсы:
Идеально подходит для масштабирования возможностей машинного обучения.
Содержит массивную библиотеку моделей с открытым исходным кодом и собственной разработки.
Решает самые сложные проблемы в области науки о данных.
Предоставляет полностью объяснимый ИИ с помощью удобных для человека визуальных представлений.
Минусы: Довольно дорого по сравнению с другими инструментами.
Цена: Зависит от размера и сложности проекта.| Доступна бесплатная пробная версия.
интегрирован с сотнями новейших алгоритмов машинного обучения, что обеспечивает полную прозрачность и контроль над процессом построения и развертывания моделей.
Начнем с того, что вы можете выбрать наиболее подходящую модель для развертывания из множества возможных. Используя DataRobot API, вы можете быстро запустить любую модель в производство, независимо от того, нужны ли вам пакетные развертывания, прогнозы в реальном времени или скоринг на Hadoop. Возможно, вам потребуется добавить несколько строк кода для настройки процесса.
Помимо того, что DataRobot уделяет особое внимание таким методам, как трансфертное обучение и машинное обучение, он также включает функции, обеспечивающие ценность для бизнеса, такие как кривые прибыли, прогнозы на основе данных и развертывание в один клик с управлением.
Платформа может быть использована для решения широкого спектра задач науки о данных, начиная от прогнозирования продаж миллионов товаров и заканчивая работой со сложными геномными данными.
8. Alteryx

Плюсы:
Интуитивно понятный интерфейс.
Готовые к использованию шаблоны прогностического моделирования.
Визуализация сложных запросов.
Подготовка, смешивание и анализ данных с помощью перетаскивания данных.
Интегрированный OCR и текстовый анализ.
Минусы:
Дорогой.
Функции вспомогательного моделирования требуют дополнительной лицензии.
Цена: От $2300 в год на одного пользователя.| Доступна 30-дневная бесплатная пробная версия.
объединяет аналитику, машинное обучение, науку о данных и автоматизацию процессов в единую сквозную платформу. Она принимает данные с сотен платформ (включая Oracle, Amazon и Salesforce), позволяя вам тратить больше времени на анализ и меньше на поиск.
Вы можете исследовать данные, создавая, получая доступ и выбирая функции с помощью визуального интерфейса программирования - Analytic Process Automation. Она позволяет вносить детальные изменения в отдельные аналитические блоки, используя готовые варианты конфигурации или добавляя собственный код на Python или R в аналитический рабочий процесс.
Alteryx позволяет быстро создавать прототипы моделей машинного обучения и конвейеров с помощью автоматизированных блоков обучения моделей. Она помогает легко визуализировать данные на протяжении всего пути решения задач и моделирования. Как? Автоматически создает таблицы, графики и отчеты на любом этапе вашего процесса.
Платформа предназначена для компаний любого размера. Если у вас средний бизнес, она поможет вам найти новые идеи и добиться высокоэффективных результатов.
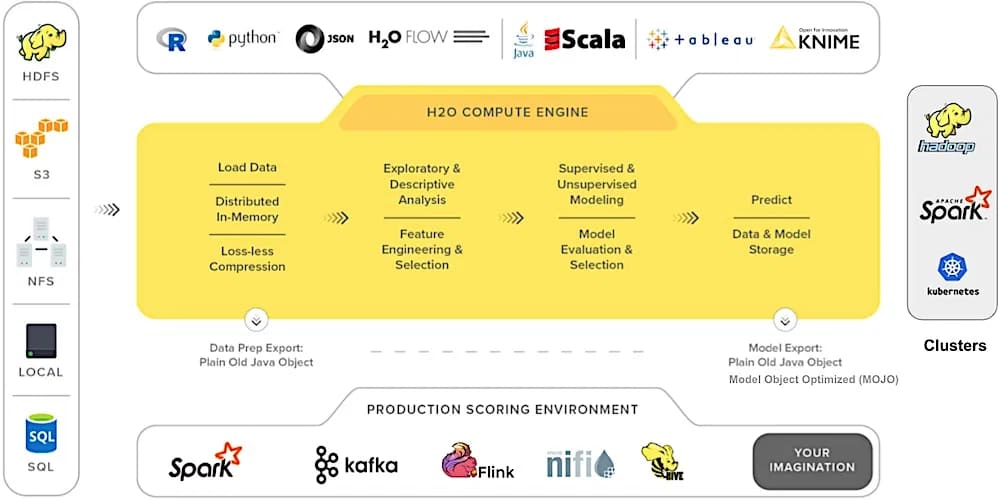
7. H2O.ai
Плюсы:
Распределенное машинное обучение в памяти.
Простота развертывания больших моделей.
Автоматизация рабочего процесса машинного обучения.
Работает на существующей инфраструктуре больших данных.
Минусы:
Ограниченные возможности обработки данных.
Отсутствие документации.
Цена: Зависит от размера и сложности проекта.| Доступна 14-дневная бесплатная пробная версия.
- это инструмент машинного обучения с открытым исходным кодом и распределенной памятью, обладающий линейной масштабируемостью. Он поддерживает почти все популярные статистические алгоритмы и алгоритмы машинного обучения, включая обобщенные линейные модели, глубокое обучение и машины с градиентным усилением. Он принимает данные непосредственно из Spark, Azure, Spark, HDFS и различных других источников в свое распределенное хранилище ключевых значений in-memory.
Для построения моделей вы можете использовать либо язык программирования R/Python, либо H2O Flow (графический блокнот), который не требует кодирования.
H2O AutoML упрощает обучение и оценку моделей машинного обучения. Это помогает автоматизировать задачи науки о данных (такие, как выбор алгоритма, итеративное моделирование, настройка гиперпараметров, генерация признаков и оценка моделей) и больше сосредоточиться на важных проблемах.
Платформа чрезвычайно популярна в сообществах Python и R и используется более чем 18 000 организаций.
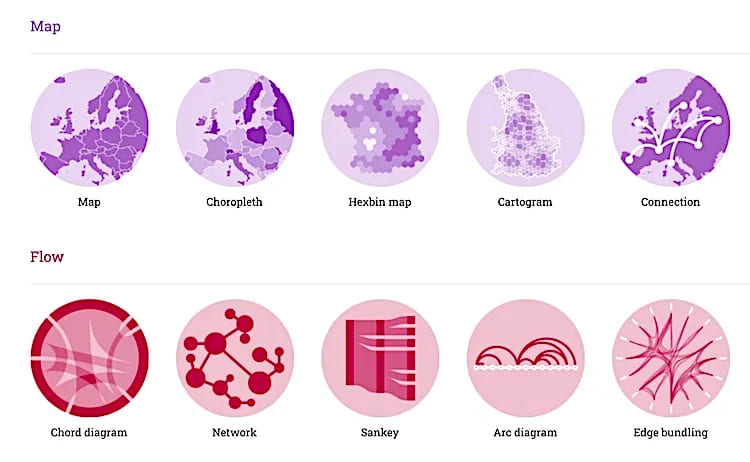
6. D3.js
Плюсы:
Легкий и быстрый.
Дает вам полный контроль над визуализацией данных.
Работает с такими веб-стандартами, как SVG и HTML.
Множество встроенных многократно используемых функций и фабрик функций.
Минусы:
Документация может быть немного улучшена.
Цена: Бесплатно.
(сокращение от Data-Driven Documents) - это библиотека JavaScript для создания динамических, интерактивных визуализаций данных в веб-браузерах. Она использует выборочные предварительно разработанные функции для создания объектов SVG, их настройки или добавления к ним динамических эффектов. К этим SVG-объектам можно присоединять большие наборы данных для создания текстовых/графических диаграмм и графиков.
D3 не имеет стандартного формата визуализации. Она позволяет создавать что угодно - от круговых диаграмм и графиков до HTML-таблиц и геопространственных карт.
Данные могут быть в различных форматах, таких как CSV или JSON. Вы можете даже написать код JavaScript для чтения других форматов данных или повторно использовать код с помощью широкой коллекции официальных и разработанных сообществом модулей.
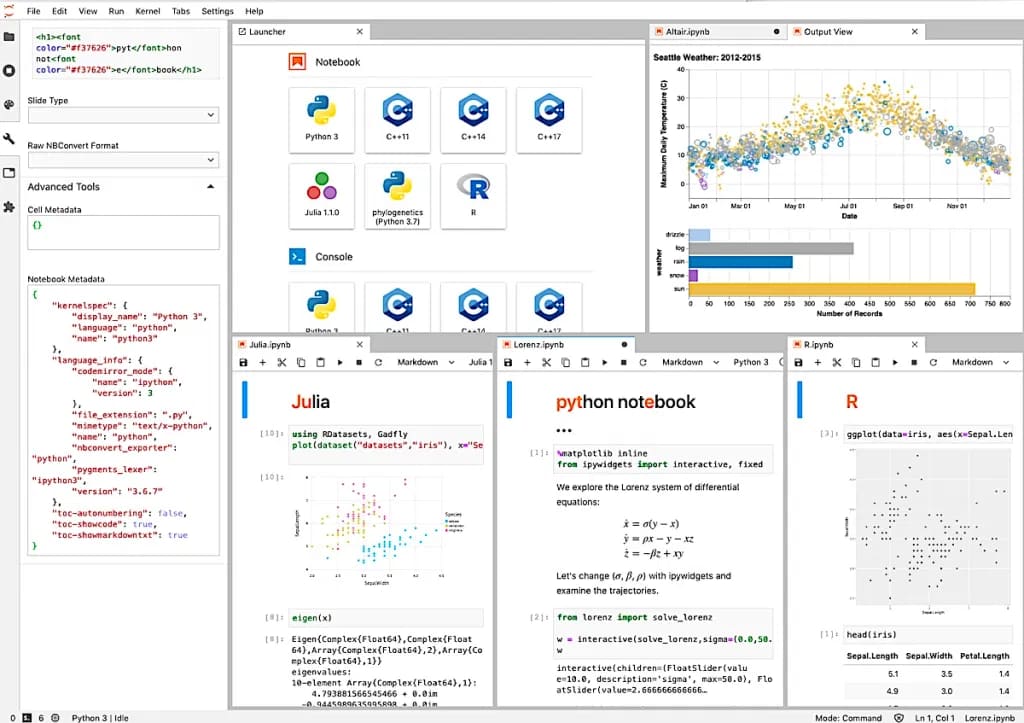
5. Project Jupyter
Плюсы:
Легкий и простой в использовании.
Отличная поддержка математических библиотек Python.
Предопределенные модели визуализации.
Легко редактировать и отслеживать потоки данных.
Автоматически создает контрольные точки.
Минусы:
Сложность работы с несколькими ядрами.
Ограниченные возможности сотрудничества.
Цена: Бесплатно.
Проект - это коллекция интерактивных веб-инструментов с открытым исходным кодом, которые ученые, изучающие данные, могут использовать для объединения программного кода, результатов вычислений, мультимедийных ресурсов и пояснительного текста в одном документе.
Хотя Jupyter существует уже несколько десятилетий, его популярность резко возросла за последние пару лет. Jupyter предлагает различные продукты для разработки программного обеспечения с открытым исходным кодом, открытых стандартов и услуг для интерактивных вычислений.
Jupyter Notebook позволяет создавать и обмениваться документами, содержащими живые уравнения, код, визуализации и повествовательный текст.
Jupyter Kernels обрабатывает множество запросов, таких как выполнение и проверка кода, и предоставляет ответ.
JupyterLab предоставляет строительные блоки (терминал, файловый браузер, текстовый редактор, расширенные выходные данные и т.д.) в интуитивно понятном пользовательском интерфейсе.
JupyterHub поддерживает множество пользователей, порождая, управляя и проксируя несколько отдельных серверов Jupyter Notebook.
Вы можете использовать эти инструменты (бесплатно) для проведения численного моделирования, очистки данных, статистического моделирования, визуализации данных и многого другого прямо из браузера.
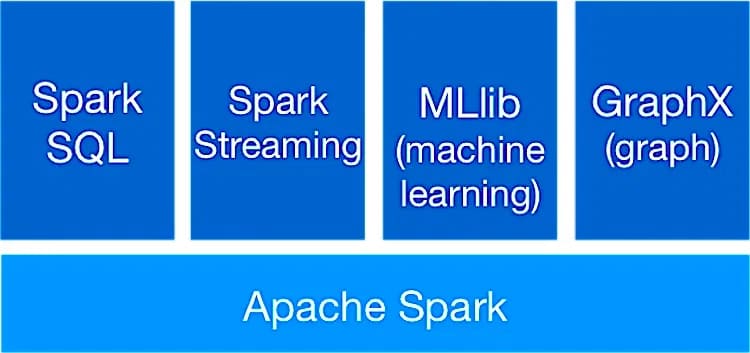
4. Apache Spark
Плюсы:
Надежность и отказоустойчивость.
Эффективно реализует модели машинного обучения для больших наборов данных.
Может получать данные из нескольких источников данных.
Поддержка нескольких языков.
Минусы:
Высокая кривая обучения.
Плохая визуализация данных.
Цена: Бесплатно.
- это механизм обработки данных с открытым исходным кодом, созданный для больших наборов данных. Он использует современный планировщик DAG, оптимизатор запросов и эффективный механизм выполнения для достижения высокой производительности как для пакетных, так и для потоковых данных. Он может выполнять рабочие нагрузки до 100 раз быстрее.
Spark использует множество библиотек, включая GraphX, MLlib для машинного обучения, Spark Streaming, SQL и DataFrames. Все эти библиотеки могут быть легко объединены в одно приложение.
Этот инструмент имеет иерархическую архитектуру главный-подчиненный. "Драйвер Spark" - это главный узел, который управляет несколькими рабочими (подчиненными) узлами и доставляет результаты данных клиентскому приложению.
Фундаментальная структура Spark - это устойчивые распределенные наборы данных, отказоустойчивый набор компонентов, которые могут быть распределены между несколькими узлами в кластере и работать с ними параллельно.
Он предоставляет более 80 операторов высокого уровня, что упрощает разработку параллельных приложений. Кроме того, вы также можете использовать Spark в интерактивном режиме из оболочек R, Python, Scala и SQL.
3. IBM SPSS Statistics
Плюсы:
Автоматизированная подготовка данных.
Позволяет точно моделировать линейные и нелинейные взаимосвязи.
Обнаружение аномалий и прогнозирование.
Поддержка алгоритмов и графиков R.
Минусы:
Большинство функций доступны в платных версиях.
Интерфейс выглядит устаревшим.
Цена: От 99 долларов США в месяц | 30-дневная бесплатная пробная версия.
- это мощная статистическая программная платформа, позволяющая максимально использовать ценную информацию, которую предоставляют ваши данные. Она предназначена для решения деловых и исследовательских задач посредством детального анализа, проверки гипотез и прогнозной аналитики.
SPSS может читать и записывать данные из электронных таблиц, баз данных, текстовых файлов ASCII и других статистических пакетов. Она может читать и записывать данные во внешние таблицы реляционных баз данных через SQL и ODBC.
Большинство ключевых функций SPSS доступны через выпадающие меню. Вы можете использовать язык командного синтаксиса 4GL для упрощения повторяющихся задач и выполнения сложных манипуляций с данными и анализа.
Исследователи рынка, добытчики данных, правительства и опросные компании широко используют эту платформу для понимания данных, анализа тенденций, проверки предположений и точных выводов.
2. RapidMiner
Плюсы:
Поставляется с богатым набором алгоритмов машинного обучения.
Интуитивно понятный графический интерфейс.
Полная автоматизация там, где это необходимо.
Расширения для подключения других полезных инструментов.
Исчерпывающие руководства.
Минусы:
Графики немного старомодны.
Большие наборы данных требуют времени для обработки.
Цена: Бесплатно.
, разработанный на основе открытой модели ядра, поддерживает все этапы метода машинного обучения, включая подготовку данных, визуализацию результатов, проверку модели и оптимизацию.
Помимо собственной коллекции наборов данных, RapidMiner предоставляет несколько вариантов создания базы данных в облаке для хранения огромных объемов данных. Вы можете хранить и загружать данные с различных платформ, таких как NoSQL, Hadoop, RDBMS и др.
Такие общие задачи, как предварительная обработка, визуализация и очистка данных, могут быть выполнены с помощью опций drag-and-drop без необходимости записывать ни одной строки кода.
Библиотека RapidMiner (содержащая более 1 500 функций и алгоритмов) позволяет подобрать оптимальную модель для любого случая использования. Она также поставляется с предварительно разработанными шаблонами, которые можно использовать в таких распространенных случаях, как выявление мошенничества, предиктивное обслуживание и отток клиентов.
Платформа широко используется для разработки делового и коммерческого программного обеспечения, а также для быстрого создания прототипов, образования, обучения и исследований. Более 700 000 аналитиков используют RapidMiner для увеличения доходов, снижения операционных расходов и предотвращения рисков.
1. Apache Hadoop

Плюсы:
Высокая масштабируемость, поскольку работает в распределенной среде.
Избыточная конструкция обеспечивает отказоустойчивость.
Может использоваться в облачной среде или на обычном оборудовании.
Хранение данных в любом формате.
Минусы:
Менее эффективен, чем другие современные фреймворки.
Требует значительных знаний для настройки, обслуживания и обновления.
Цена: Бесплатно.
- это экосистема утилит с открытым исходным кодом, которая в корне меняет способы хранения, обработки и анализа данных. В отличие от обычных платформ, она позволяет выполнять множество различных типов аналитических рабочих нагрузок на одних и тех же данных, в одно и то же время, в больших масштабах на стандартном промышленном оборудовании.
Hadoop распределяет большие наборы данных и аналитические задания по узлам вычислительного кластера, преобразуя их в более мелкие рабочие нагрузки, которые могут выполняться параллельно. Она может обрабатывать как структурированные, так и неструктурированные данные и масштабироваться от одной машины до тысяч устройств.
Этот инструмент состоит из пяти основных модулей:
Распределенная файловая система Hadoop (HDFS) может хранить большие наборы данных на узлах отказоустойчивым способом.
Еще один посредник по согласованию ресурсов (YARN) отвечает за планирование задач, управление ресурсами кластера и планирование заданий, выполняемых в Hadoop.
MapReduce - это механизм обработки больших данных и модель программирования, которая обеспечивает параллельное вычисление больших наборов данных.
Hadoop Common состоит из библиотек и утилит, необходимых для других модулей Hadoop.
Hadoop Ozone - это хранилище объектов, оптимизированное для миллиардов небольших файлов.
В целом, Hadoop включает в себя новые форматы данных (например, данные о настроениях в социальных сетях и потоки кликов) и помогает аналитикам принимать более эффективные решения на основе данных в реальном времени.
Другие не менее замечательные инструменты для работы с данными
10. Tableau
Подходит для: малого бизнеса для визуализации данных и получения содержательной информации.
- это платформа визуальной аналитики, которая позволяет вам видеть и понимать данные. Она предлагает широкий спектр вариантов источников данных, к которым можно подключаться и получать данные.
Самое лучшее в Tableau - это то, что для извлечения значимых выводов не требуется кодирование или технические навыки. Вы можете использовать ее функции на основе пользовательского интерфейса для создания пользовательских информационных панелей и анализа отчетов. Благодаря простоте использования и продвинутой визуализации Tableau заинтересовал специалистов по работе с данными, аналитиков, руководителей предприятий и преподавателей.
11. Databricks Lakehouse
Подходит для: специалистов по обработке данных и инженеров для совместной работы при любых рабочих нагрузках.
объединяет все ваши рабочие нагрузки, связанные с данными, аналитикой и искусственным интеллектом, в единую платформу. Она позволяет использовать инструменты бизнес-аналитики непосредственно на исходных данных, сокращая задержки и повышая эффективность затрат.
Платформа поддерживает широкий спектр рабочих нагрузок, включая машинное обучение, SQL, аналитику и многое другое. Она предлагает бесшовную интеграцию с AWS, Azure и Google Cloud.
Созданная на основе открытого исходного кода и открытых стандартов, встроенные возможности Databricks для совместной работы расширяют возможности командной работы и ускоряют внедрение инноваций. В целом, это решение ускорит ваше видение науки о данных и поможет вам видеть дальше дорожной карты.
12. TIBCO Data Science
Подходит для: студентов и преподавателей, создающих сложные процессы обработки данных, статистики и машинного обучения.
От подготовки данных и создания моделей до развертывания и мониторинга, инструменты позволяют автоматизировать утомительные задачи и создавать бизнес-решения, используя алгоритмы машинного обучения.
Настольный пользовательский интерфейс включает более 16 000 функций, которые вы можете использовать для создания сложных рабочих процессов расширенной аналитики. Также есть возможность интегрировать R, Python и другие узлы в конвейеры.
Кроме того, встроенные узлы дают вам доступ к аналитике графов, текстов, временных рядов, регрессии, нейронных сетей, статистическому управлению процессами и многомерной статистике.
TIBCO также предлагает широкую поддержку корпоративного управления в таких отраслях, как здравоохранение, фармацевтика, производство, финансы и страхование.
13. Weka
Подходит для: решения реальных задач интеллектуального анализа данных
- это набор инструментов визуализации и алгоритмов для анализа данных и прогностического моделирования. Все они доступны бесплатно по лицензии GNU General Public License.
Более конкретно, Weka содержит инструменты для предварительной обработки данных, классификации, регрессии, кластеризации и визуализации. Для людей, которые давно не программировали, Weka с ее графическим интерфейсом пользователя обеспечивает легкий переход в мир науки о данных.
Пользователи могут экспериментировать со своими наборами данных, применяя различные алгоритмы, чтобы увидеть, какая модель дает наилучший результат. Затем они могут использовать инструменты визуализации для изучения данных.
Часто задаваемые вопросы
В чем разница между наукой о данных, AI и ML?
Наука о данных - это широкая область знаний, которая включает в себя предварительную обработку, анализ и визуализацию структурированных и неструктурированных данных. Полученные из данных выводы затем применяются в широком спектре областей применения.
Искусственный интеллект означает обучение машины подражать человеческому поведению. Цели исследования ИИ включают представление знаний, планирование, обучение, рассуждения, обработку естественного языка, восприятие и способность манипулировать объектами.
Машинное обучение - это подмножество ИИ, которое фокусируется на том, как использовать данные и алгоритмы, чтобы имитировать способ обучения людей. Чем больше данных (также называемых обучающими данными) получает модель машинного обучения, тем точнее она делает прогнозы, не будучи явно запрограммированной на это.
Какие этапы включает в себя наука о данных?
Наука о данных включает в себя шесть итерационных этапов.
Планирование: Определите проект и его предполагаемые результаты.
- Построение модели данных: Используйте соответствующий инструмент науки о данных для создания моделей машинного обучения.
- Оценить: Используйте метрики оценки и визуализацию для измерения производительности модели на основе новых данных.
- Объяснить (простыми словами) внутреннюю механику моделей машинного обучения.
- Развертывание хорошо обученной модели в безопасной и масштабируемой среде.
- Контролировать работу модели, чтобы убедиться, что она работает правильно.
Что нужно учитывать перед выбором инструмента для работы с данными?
Ниже перечислены ключевые характеристики, на которые следует обратить внимание при выборе платформы для анализа данных:
- Она должна позволять нескольким пользователям работать вместе над одной моделью.
- Должна включать поддержку последних приложений с открытым исходным кодом.
- Должна быть масштабируемой.
- Должна иметь возможность автоматизировать утомительные задачи.
- Должна иметь возможность легко внедрять модели в производство.
Как наука о данных помогает бизнесу?
Наука о данных играет важную роль в анализе состояния бизнеса. Она извлекает ценную информацию из необработанных данных и прогнозирует степень успешности продуктов и услуг компании. Она также помогает выявлять неэффективные производственные процессы, ориентироваться на нужную аудиторию и набирать нужные кадры для организации.
Некоторые отрасли используют науку о данных для повышения безопасности своего бизнеса и защиты конфиденциальной информации. Банки, например, используют алгоритмы машинного обучения для выявления мошенничества на основе обычной финансовой деятельности клиента. Эти алгоритмы оказались гораздо более эффективными и точными в выявлении мошенничества, чем ручные расследования.
Согласно отчету GlobalNewswire, глобальный рынок платформ data science достигнет 224 миллиардов долларов к 2026 году и будет расти со скоростью 31 процент в год.