Предвидение сердечной недостаточности с помощью машинного обучения

Одним из способов, с помощью которого врачи могут предупредить о надвигающейся сердечной недостаточности, является обнаружение избытка жидкости в легких, и исследователи MIT разработали новый инструмент машинного обучения, который может протянуть им руку помощи. Алгоритм способен обнаруживать тяжелые случаи этого состояния с высоким уровнем точности, и исследователи, стоящие за ним, надеются, что его можно будет адаптировать для помощи в управлении другими состояниями.
Исследование было проведено в Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института (CSAIL) и вписывается в ряд других многообещающих инструментов машинного обучения и искусственного интеллекта, которые меняют медицинский диагноз. Благодаря возможностям современных вычислительных систем, эти алгоритмы способны просматривать данные медицинской визуализации, чтобы обнаружить тонкие, но критические изменения в состоянии человека, которые врачи не могут увидеть, открывая некоторые захватывающие возможности.
Это может означать выявление пропущенных диагнозов рака с помощью компьютерной томографии или обнаружение признаков болезни Альцгеймера за годы до того, как они станут видимыми для врачей. Мы также рассмотрели, как использование искусственного интеллекта для анализа результатов электрокардиограммы могло бы помочь врачам определить пациентов, наиболее подверженных риску сердечной недостаточности, путем выявления дисфункции левого желудочка, и это новое исследование следует аналогичным путем, хотя и фокусируется на другом механизме.
Врачи используют рентгеновские снимки легких для оценки скопления жидкости у пациентов, подверженных риску сердечной недостаточности, при этом тяжесть состояния, известного как "отек легких", затем определяет курс лечения. Проблема в том, что эти оценки часто основаны на таких тонких особенностях, что они могут привести к непоследовательным диагнозам и планам лечения.
Чтобы задействовать машинное обучение, команда обучила свои алгоритмы на более чем 300000 рентгеновских снимках и соответствующих отчетах, написанных радиологами. Это включало разработку определенных лингвистических правил, чтобы обеспечить единообразный анализ данных по множеству выборок.
"Наша модель может превратить как изображения, так и текст в компактные числовые абстракции, на основе которых может быть получена интерпретация", - говорит соавтор статьи Гитика Чаухан. "Мы обучили его минимизировать разницу между представлениями рентгеновских изображений и текстом радиологических отчетов, используя отчеты для улучшения интерпретации изображений".
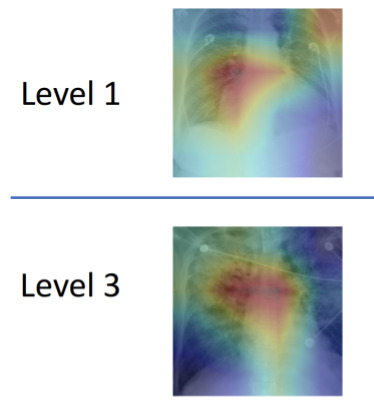
При тестировании команда попросила алгоритм машинного обучения проанализировать отдельные рентгеновские снимки и классифицировать степень отека в диапазоне от 0 (здоровый) до 3 (очень, очень плохо). Алгоритм был в состоянии диагностировать правильный уровень отека более чем в половине случаев, но, что еще более впечатляюще, был в состоянии точно диагностировать случаи третьего уровня в 90% случаев.
Есть надежда, что этот инструмент может помочь врачам лучше справляться с проблемами с сердцем, но отеки связаны с рядом состояний, включая сепсис и почечную недостаточность, поэтому потенциал алгоритма может быть широким. В настоящее время исследователи работают над внедрением этого инструмента в рабочий процесс отделения неотложной помощи Медицинского центра Бет Исраэль в Бостоне в ближайшие несколько месяцев.
"Этот проект призван расширить рабочий процесс врачей за счет предоставления дополнительной информации, которая может быть использована для информирования их диагнозов, а также для проведения ретроспективного анализа", - говорит аспирант Руичжи Ляо (Ruizhi Liao), который был одним из ведущих авторов статьи.
Источник: